
Word2Vec and Elasticsearch for Recommendations
What are content-based recommender systems?
- Content-based recommender systems use item features and characteristics to produce similarities according to a similarity metric. Then, for a certain target product, these systems recommend the most similar products using the previously computed similarities. In a practical approach, if we consider the items as movies in the Netflix catalog, the features could be the product descriptions, movie genre, cast, and producers. In this sense, we group movies with similar characteristics, that is with similar descriptions, genres or actors who take part in that film. A good example is if we think about the Star Wars movies. Since all the movies fall into the same category and have a similar cast and descriptions, if we are viewing a page where we’re shown information about Episode IV – A New Hope, a good recommendation of another page would be Episode V – The Empire Strikes Back, because these movies are closely related to each other.
How do we approach this mathematically?
-
Well, we use vectors, which can be called embedding vectors. If somehow we could find a way to represent items as vectors in a certain vector space, we could use numerous mathematical calculations on these vectors to compute similarities. One of these possibilities is the cosine similarity, which is a good way of providing a similarity measure between non-binary(or categorical) vectors. What this means is that, if we had two items, A and B, we could infer two vector representations of these items,
vec_A, andvec_Bwhich would represent these items in a certain vector space, with a certain length, we could compute the cosine similarity between them which would numerically express the similarity between A and B. -
In the snippet below we’re creating two random NumPy vectors of a fixed length of 128 units between -1 and 1, using a uniform distribution function.
import numpy as np
vec_A = np.random.uniform(low=-1, high=1, size=128)
vec_B = np.random.uniform(low=-1, high=1, size=128)
What is the Cosine Similarity?.
- As previously said, cosine similarity measures the similarity between two vectors. It does so, by computing the cosine of the angle between the two vectors, which means that higher angles between two vectors representing two items will have a lower cosine value, than lower angles.
- The calculation is done by dividing the dot product of the two vectors by the multiplication of their euclidean norms.
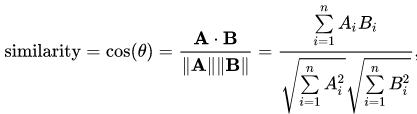
- In the snippet below we’re using sklearn.metrics.pairwise module which contains the cosine similarity function to calculate the cosine similarity between the two previously created vectors.
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(vec_A.reshape((1, 128)), vec_B.reshape((1, 128))).reshape(1)
How do we obtain these vectors?
-
First, we need to consider this article is related to Natural Language Processing. Taking this into consideration, there are multiple ways of responding to this question. We need to consider that standard integer encodings or one-hot-encoding representations do not help capture the semantic meaning of words in a text, so we need to think of other ways to do this.
-
More recent publications include Seq2Vec, Doc2Vec, or even Amazon’s BlazingText which are all deep learning strategies, but in this post, I’m going to talk about Word2Vec and how we can use Word2Vec to produce document embedding vectors.
What is Word2Vec?
-
You can find the original publication here. We can refer to the TensorFlow implementation which implements some ideas of the paper above. There is also this very interesting article on KDNuggets.
- Word2Vec is a recurrent neural network architecture that attempts to learn embedding vectors for words in a text corpus. In the previous TensorFlow guide they explain the Skip-Gram model implementation but there also exists the Continuous bag-of-Words model.
- Often these datasets contain millions of words and standard feed forward-neural networks applied a full softmax function over the vocabulary, as an output layer, which was highly inefficient. The paper, offers multiple ways of solving this issue, either through Hierarchical Softmax (using Huffman Trees) or using Noise Contrastive Estimation (NCE). Here, we’ll approach NCE. NCE solves this issue, by differentiating data from noise. In reality, since we’re only interested in choosing noise words for not to calculate network weights, what we’re doing is called Negative Sampling. For every word, called context word we choose a few negative sampling words, that do not appear together in a certain window (group of words) and choose not to calculate the weights for these words.
- We can also use word sub-sampling which we can do to filter the most frequent words in the dataset corpus.
- The input data is vectorized in one-hot-encodings, but the technique talked about in the previous point is used to improve efficiency.
- There is a projection layer to reduce the dimensionality of the encoding vectors to a fixed vector length.
- After we train a Word2Vec model, we can get predictions of embedding vectors for words in an item description.
- To get item vectors we could, for instance, average the embedding vectors for each word in a description.
- You could train this neural network using cloud services like AWS Sagemaker.
Where does Elasticseach fit in?
- Well if we manage to obtain a working way of obtaining item vectors, we need to take into account that similarity comparison is no easy task. After obtaining the item vectors we need to calculate similarities for every pair of items we know to exist. We can construct a similarity matrix of items, where we are only interested in half of the matrix since the similarity of items A and B is the same as items B and A. After this, we need to make a search for each item, for the highest K similarities so that we can see which items are supposed to be recommended. This computational process has O(n²) complexity, where
nis the number of items. This is similar to the nearest neighbor search. - One of the options is to store and perform this search in an Elasticsearch cluster, that can act as a database. According to this article, we could create an Elasticsearch index in a cluster whose mappings contain a
dense_vectorrelated to a certain field identified by a name. - Elasticsearch provides the
cosineSimilarityfunction for querying purposes, where it returns the items more similar to the one provided in the parameters.