
Hierarchical Classification with K-Means and a Neural Network
In this blog post I’m going to be describing a proof of concept I made experimenting with hierarchical multiclass classification usin K-means clustering and a simple Artificial Neural Network. The full project code can be found here.
Hierarchical Classification
Hierarchical classification is a type of classification task where you have a hierarchy tree and each label which is not at the root of the tree is associated with a previous label at an upper level. This means that every tree node, is a possible classification label and the tree leafs are the most specific labels which we can classifify a sample with.
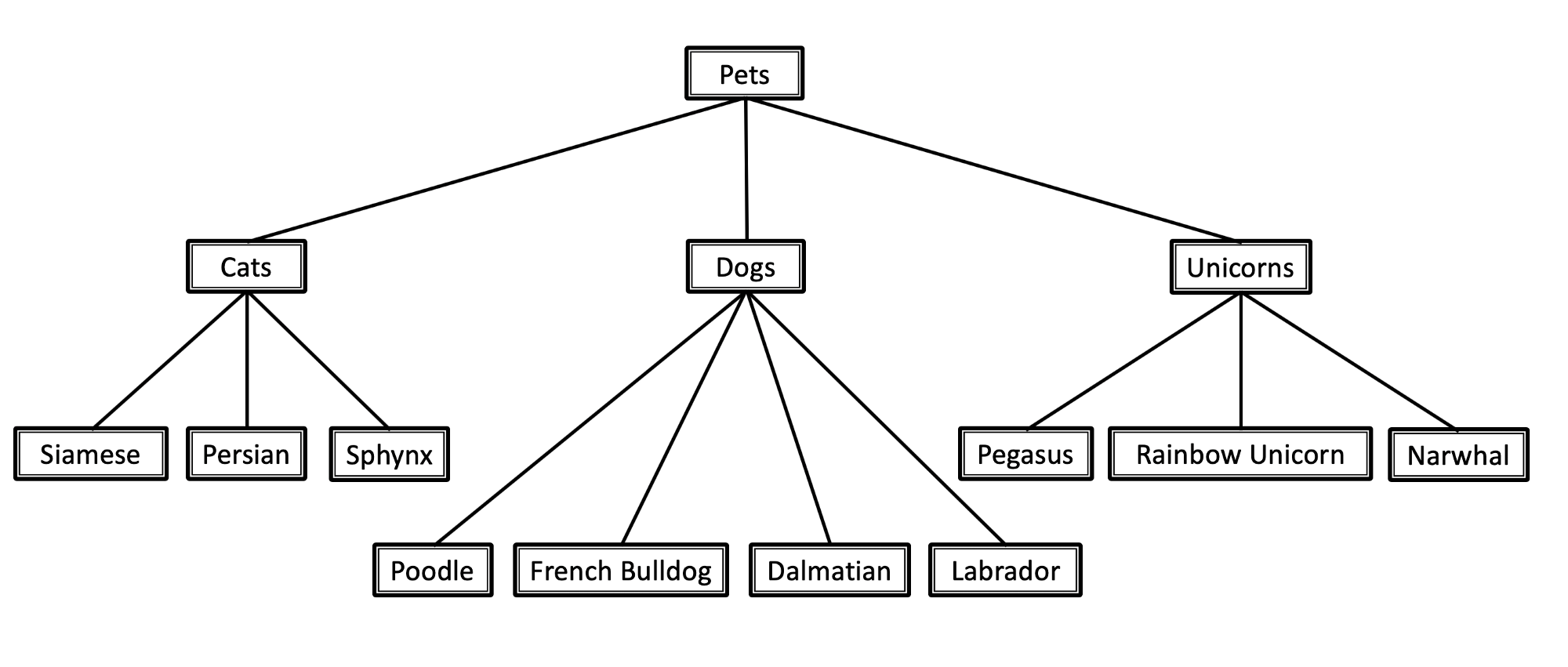
Image taken from this blog post.
In this example we can see that the label Persian follows a hierarchical structure made of Pets > Cat > Persian.
If we interpret this tree as a graph, we can conclude that this is a directed acyclic graph where each path you take will lead you to one and only one leaf node.
So, in terms of classification, classifying something as a Persian will also classify it as a Cat and a Pet automatically, since there are no other paths in the graph which will lead us to that specific node.
In practice, what we want is to be able to classify the most specifc category for each sample we have in a dataset.
Chosing a Dataset
For this POC I used this public Kaggle dataset which is a list of amazon public item reviews made by customers about sold products. Each product is labeled into categories which are structured into 3 different levels. It is not mandatory that each product has three levels of categories, they can have only two or even one.
The original datasets are divided between test and validation sets. The only contents which were not present there were the parsed versions of the 40k and 10k test and validation sets.
Both implementations for design reasons, can only output categories which were present in the train dataset (I know, I know…) so I evaluated the impact this could take in the final metric calculation using as follows:
import pandas as pd
# reading the train dataframe
df1 = pd.read_csv("data/amazon/train_parsed_40k.csv")
# reading the validation dataframe
df2 = pd.read_csv("data/amazon/val_parsed_10k.csv")
# a set of unique cateogories of the training dataframe
cats1 = set(df1['CATEGORY'].unique())
# a set of unique cateogories of the validation dataframe
cats2 = set(df2['CATEGORY'].unique())
# which categories are in the validation dataframe but are not in the test dataframe
# these categories are the ones we cannot predict
missing = cats2 - cats1
missing
>> {'coatings batters', 'hydrometers', 'chocolate covered nuts', 'breeding tanks', 'flying toys', 'dried fruit', 'exercise wheels', 'shampoo', 'lamb'}
# how many rows of the validation dataframe have these categories
len(df2[df2['CATEGORY'].isin(missing)])
>> 11
You can construct the datasets to be used in the code by running python -m entrypoint parse, after
you clone the repository.
Since there are only 11 rows which we won’t be able to predict out of 10k this isn’t a big deal.
Transfer Learning
Before jumping into using K-means clustering, I had to find a way to represent the movie reviews into a vectorized format. To simplify this task, since all the reviews are in English, I used the Google Universal Encoder which we can download from TensorHub which will output a 512-dimensional embedding vector representing the sentence provided as input.
import os
import tensorflow_hub as hub
TSFLOW_UNIV_ENC_URL = "https://tfhub.dev/google/universal-sentence-encoder/4"
def load_universal_encoder() -> Any:
"""
A function which loads the google universal encoder
from TensorHub. It will cache it after it runs the first
time.
Returns:
A Google Universal Encoder instance.
"""
os.environ['TFHUB_DOWNLOAD_PROGRESS'] = "1"
encoder = hub.load(TSFLOW_UNIV_ENC_URL)
return encoder
Metric
The main metric to be calculated was a hit ratio, basically computing the number of times the model could guess the correct category out of the total validation samples. We return the value in percentage.
def hit_ratio(df: pd.DataFrame) -> float:
"""
A function which calculates the hit ratio of a results dataframe.
Args:
df pd.DataFrame A pandas dataframe with computed results
and a prediction column for each product
Returns:
float The hit ratio, that is, the number of times it matched
the correct category out of the total length in percentage.
"""
counter = len(df[df[PREDICTION_COL] == df[CATEGORY_COL]])
ratio = round((counter / len(df)), 4) * 100
return ratio
K-Means Clustering
The idea behind using K-means clustering for hierarchical classification is:
- By using the embedding vectors provided by the universal encoder we can use k-means to cluster the vectors into N different clusters, where N is the number of possible different categories present in the dataset.
- After this, for every validation sample vector we verify the cluster on which it is located, and extract the most specific category for that sample. This makes an association between that cluster and that category label. Then, inside a dictionary we build a histogram where for each cluster prediction we have the number of associations between each category and each cluster.
- Finnaly, we can now find a heuristic which can help us map a cluster ID into a category name. To simplify things, I choose for each cluster the label with the highest association count. However there are more possibilities for this, such as doing a similar implementation to what is done in calculating TF-IDF in text processing tasks.
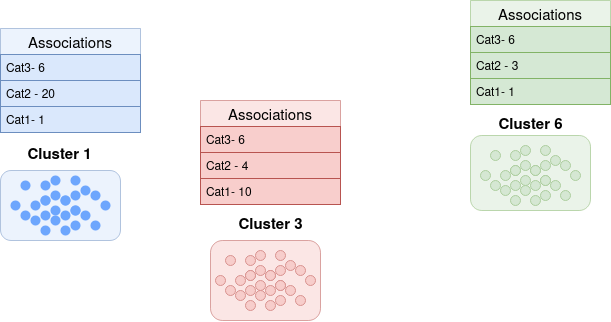
Below, the build_histogram function builds the cluster-category association histogram
and the build_label_mapper constructs a mapping dictionary between a cluster and a category.
def build_histogram(df: pd.DataFrame) -> defaultdict:
"""
A function which builds a histogram for the number of
matches a category has for each cluster. A cluster
might get matched with multiple categories, this way
we can evaluate the highest category match per cluster and
later on associate each cluster with a category.
Args:
df pd.DataFrame A pandas dataframe with computed results
and a prediction column for each product
Returns:
defaultdict A default dictionary whose default value is
another defaultdictionary whose default value is int(0)
"""
histogram = defaultdict(
lambda: defaultdict(int)
)
for _, row in tqdm(df.iterrows(), desc="Building label histogram....", total=len(df)):
prediction = row[RAW_PREDICTION]
label = row[CATEGORY_COL]
histogram[prediction][label] += 1
return histogram
def build_label_mapper(df: pd.DataFrame) -> dict:
""" A function which maps a cluster label prediction
to a category based on a computed histogram, taking into
account a provided results pandas dataframe.
Args:
df pd.DataFrame A pandas dataframe with computed results
and a prediction column for each product
Returns:
dict A dictionary which maps a cluster label to a category name.
"""
histogram = build_histogram(df=df)
mapper = dict()
for prediction, count in tqdm(histogram.items(), desc="Building label mapper...", total=len(histogram)):
label = max(count, key=lambda key: histogram[prediction][key])
mapper[prediction] = label
return mapper
The hit ratio revolved around 59% to 60%
You can run the kmeans approach using python -m entrypoint kmeans, after cloning the repository.
Comparing the results with an ANN
The implemented neural network was a simple feed forward neural network with 2 dense hidden layer and a final dense output layer, with a softmax activatio function over the number of possible categories. Since the labels were the one hot encoded versions of the categories each predicted final tensor would be compared with the correct one hot encoded category real label, and the categorical cross entropy loss will be computed.
class ANN(Model):
""" An artificial neural network model using the tensorflow subclassing API.
It takes into account the number of available categories
which we can predict.
"""
def __init__(self, n_categories: int):
"""
RNN's constructor.
Args:
n_categories: int The number of categories.
"""
super().__init__()
self.dense = Dense(units=1000, activation="relu")
self.out_layer = Dense(units=n_categories, activation="softmax")
self.compile(
optimizer=Adam(),
loss=CategoricalCrossentropy(from_logits=True),
metrics=[CategoricalAccuracy()]
)
def call(self, inputs):
"""
A function which is executed during training at each
iteration.
Args:
inputs: A tensor which will be provided as an input
which will be an embedding vector.
"""
x = self.dense(inputs)
return self.out_layer(x)
You can run the ANN approach using python -m entrypoint kmeans, after cloning the repository.
The calculated hit ratio was around 65,7% so a bit above the K-means implementation.